


370
|
身边有很多写SQL很厉害的数据分析人员,数据治理好了、对数据仓库、业务需求都很熟悉,因为对机器学习算法、数据挖掘模型不是很熟悉,没法独立产出更高阶的分析结果。 哪怕厉害的分析师自己花费九牛二虎之力,做出了模型,还要对模型不断地调优,一趟操作下来,也累得够呛。 能否在没有算法工程师支持的情况下,做模型训练和特征识别,快速调整策略呢? 最近体验了 Amazon SageMaker Canvas 这样一款人人自助式机器学习工具,我找到了答案。 一、产品体验 1. 数据集选择和介绍 笔者使用了Kaggle的公开的银行数据集。 包含了14个特征:序号、客户ID、名字、信用分、地区、性别、年龄、保有期、余额、购买的产品数量、是否有信用卡、是否活跃用户、固定工资、是否正在从银行中取钱。 其中,需要构建的预测模型是:是否将会从银行中取出钱。 基于该数据集,笔者完整地体验了 Amazon SageMaker Canvas 数据集管理、建模、预测的流程。 2. 导入数据和预览 在导入了数据集之后,系统就给了一些特征提示。
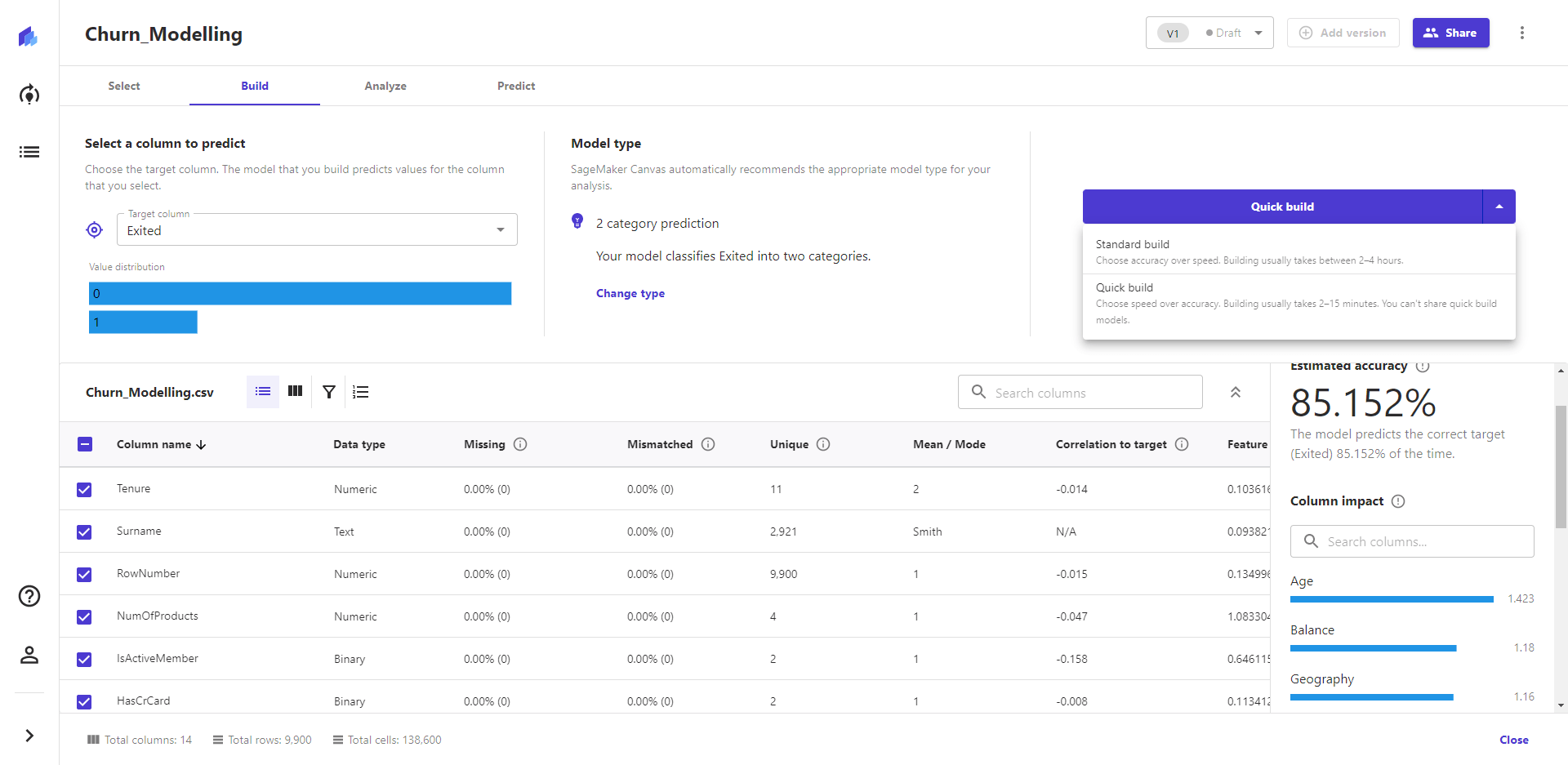
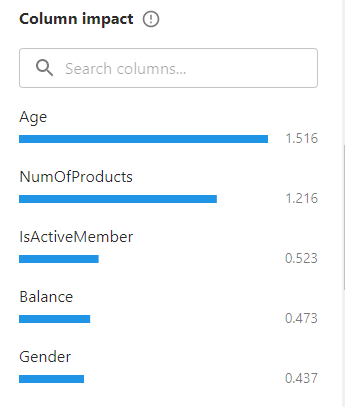
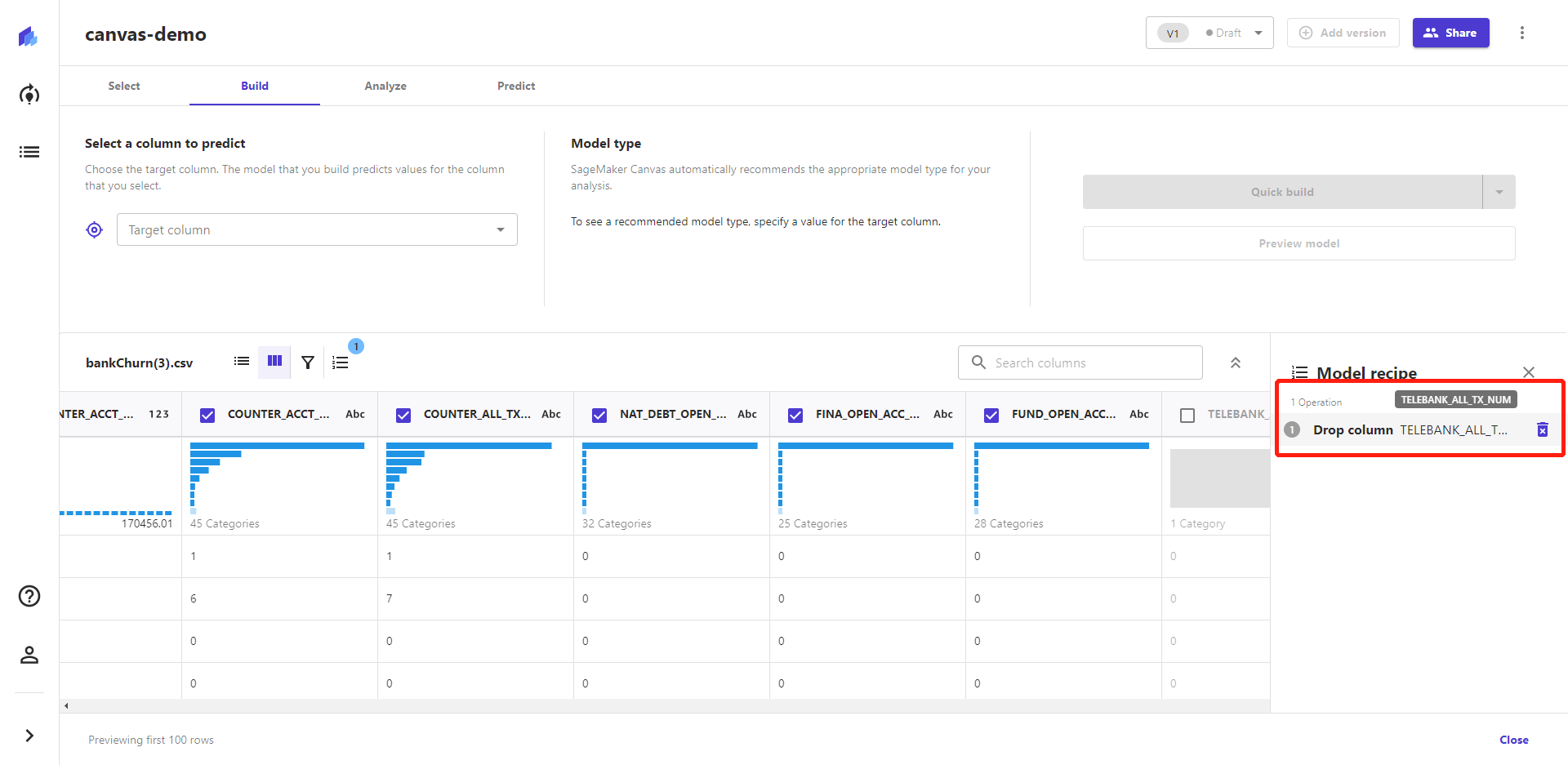
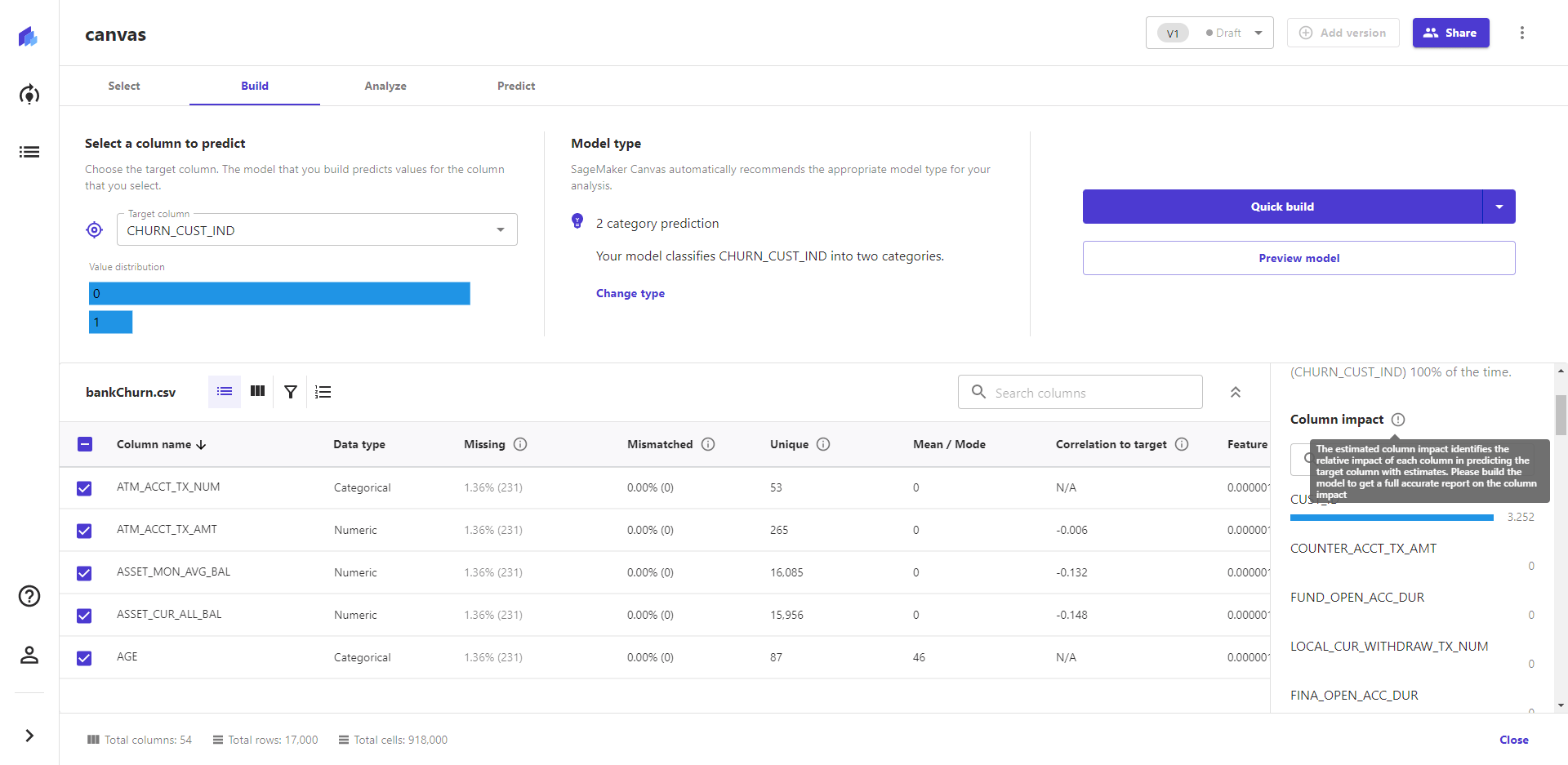
也可以在此处对特征值进行初步的筛选,缺失值、类型不匹配、唯一值等,还可以初步判断特征和目标特征之间的线性相关关系、影响因子。 给出就给用户一些特征权重的提示,能够快速地调整选中的特征。 比如一些非关键特征:Surname、CustomerId,就被我去掉了。这样,也适当减少不必要的计算量,提高模型构建速度。 3. 快速构建和标准构建 系统提供了两种构建模式:标准模式、快速模式。 快速构建模型模式,模型构建速度更快,精确度则要低一些。标准模式则反之,模型构建耗时更多,精准度则要高一些。
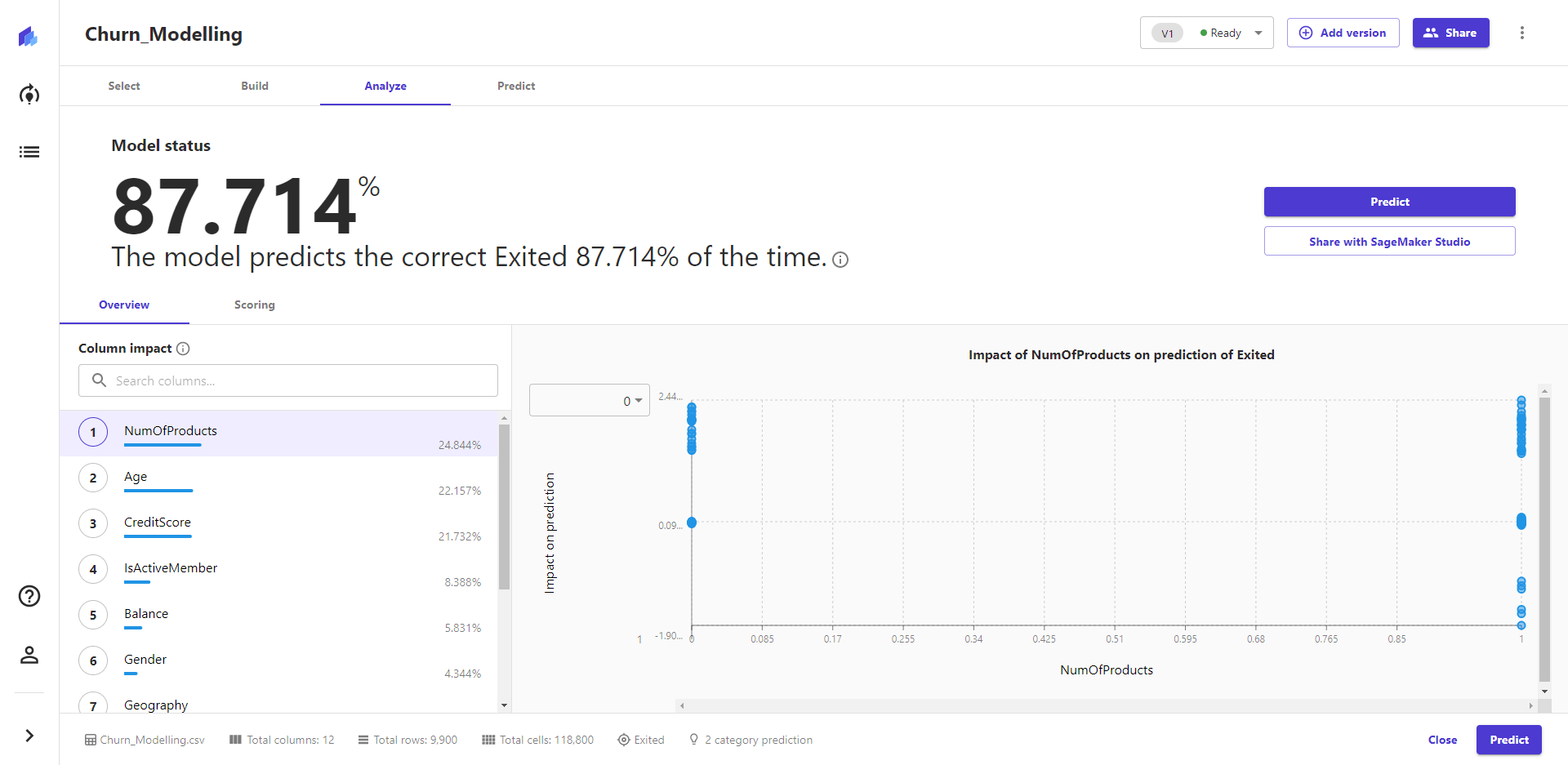
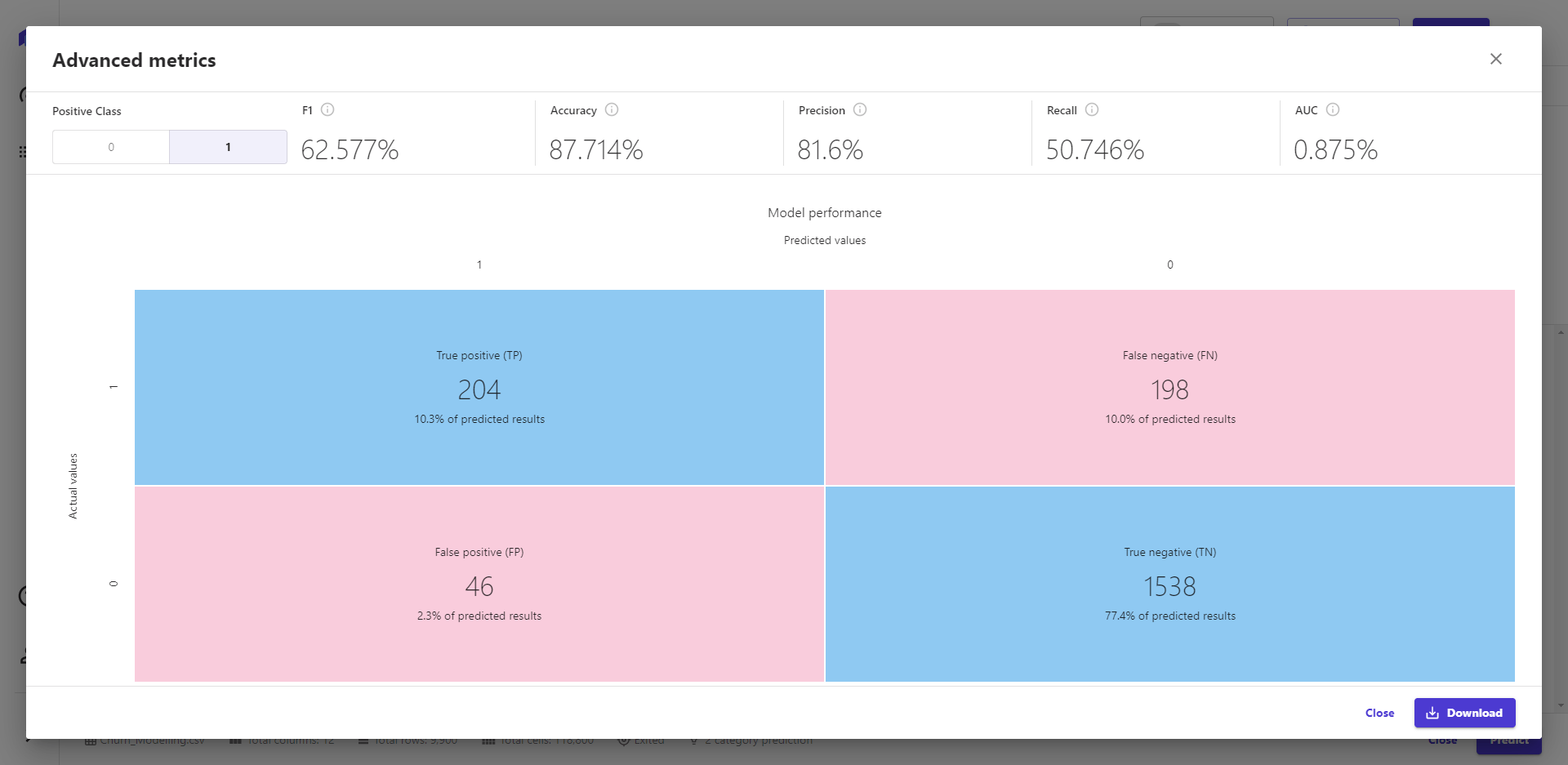
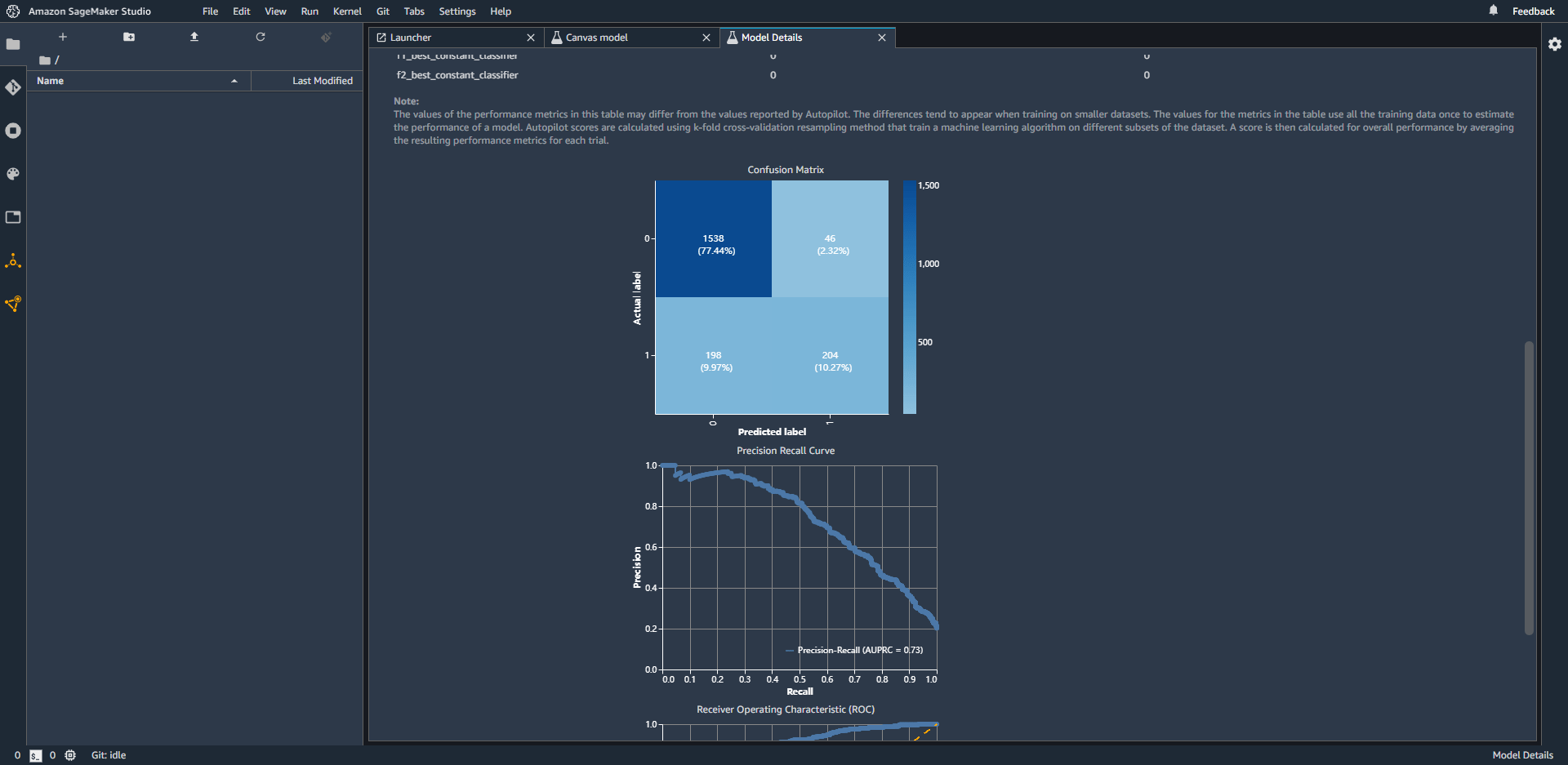
4. 模型构建结果 模型的预测准确率。 模型训练完,在概览页可以看到预测的精准度为87.714%,也可以看到各个特征的影响值。 在得分页,可以看到具体的预测准确数和错误数。
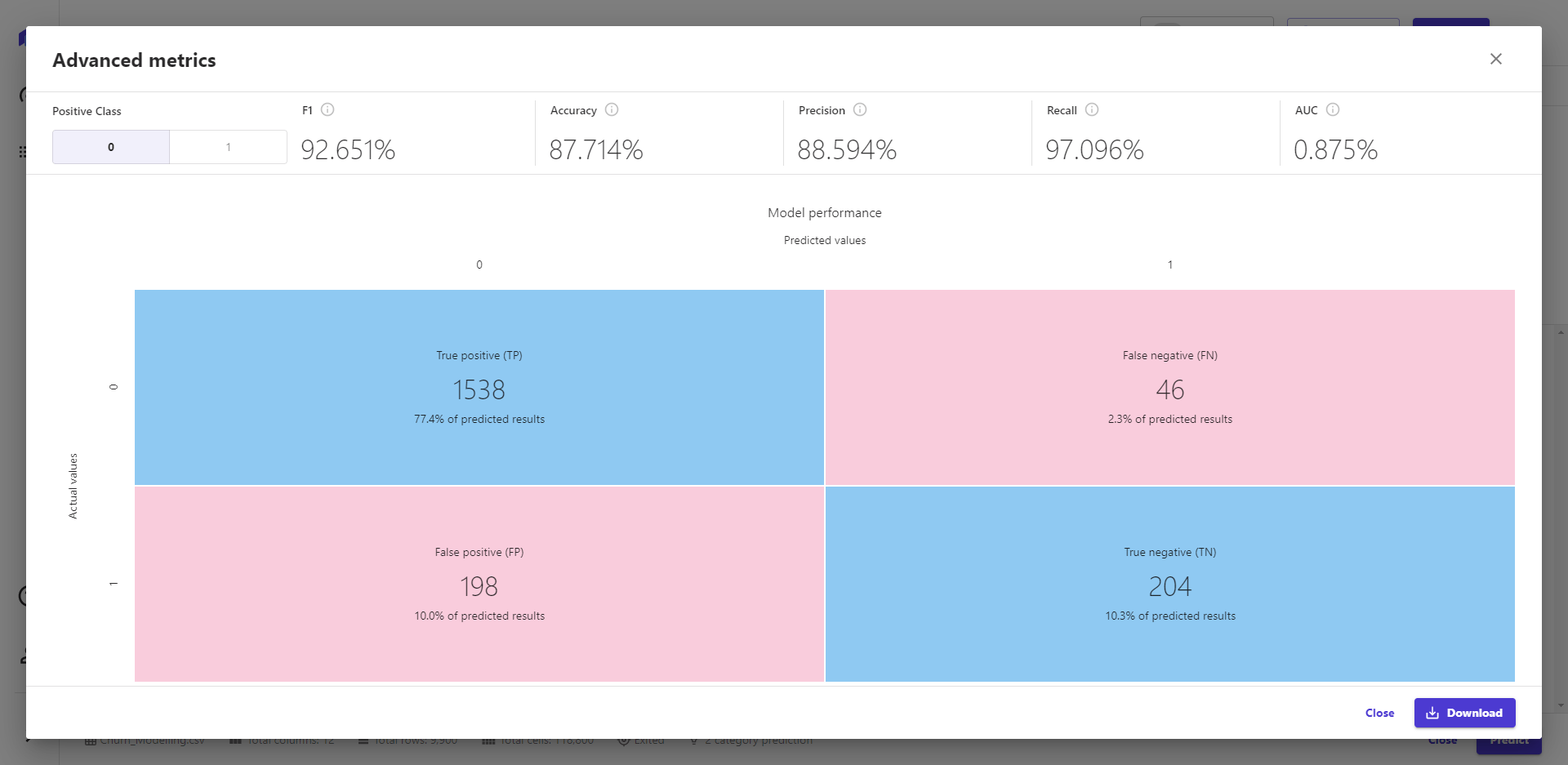
点击高级指标,也看到不同结果,模型的准确度、精确度、召回值、AUC值。
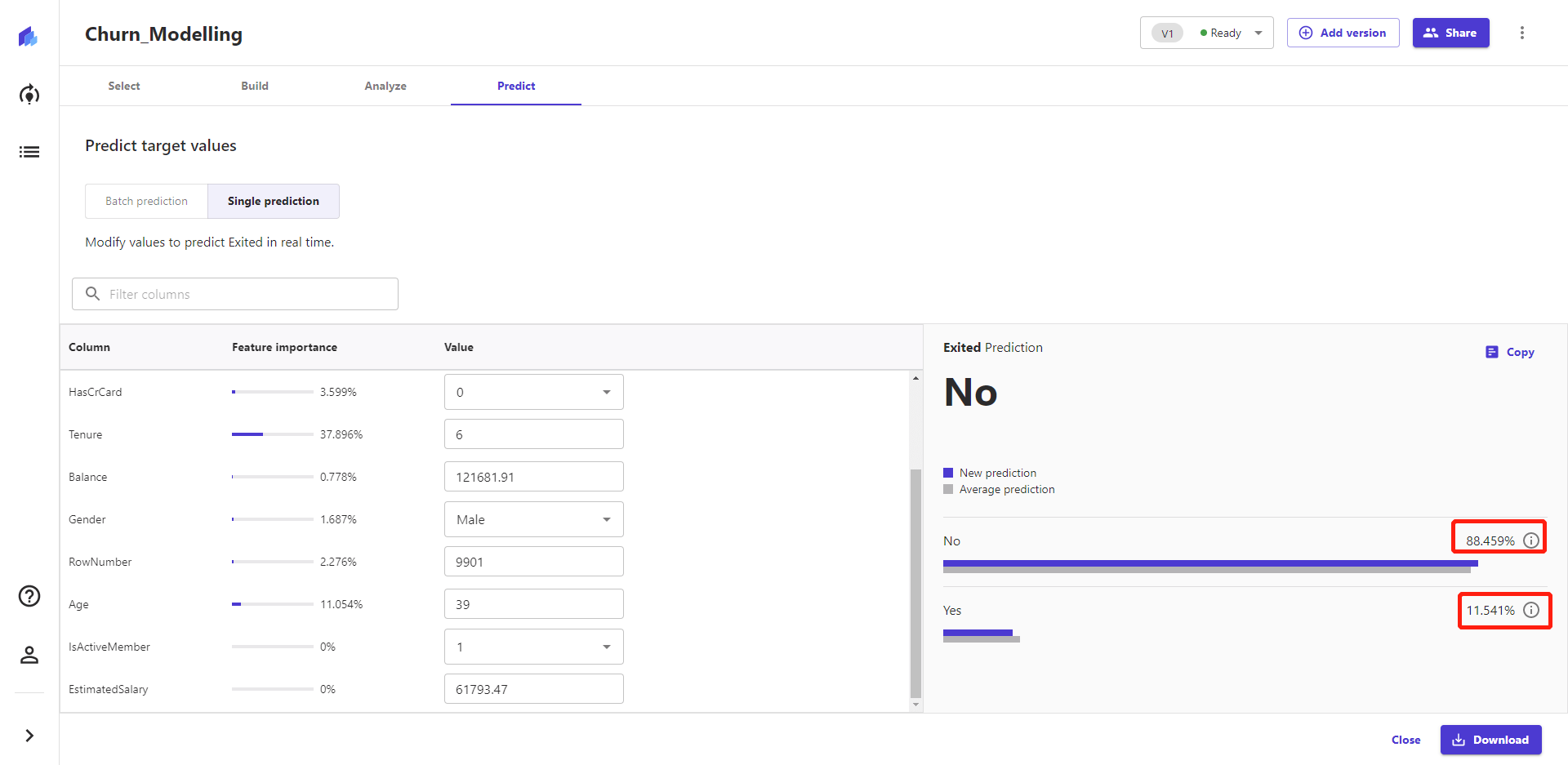
5. 利用模型进行预测 模型构建完成后,可以利用模型进行预测对单个数据进行预测。
也可以对数据集进行预测,系统会给出可能性。 二、应用前景介绍 笔者所在的领域,是直播领域。用户运营、数据分析师们日常会对投放转化、用户活跃、用户留存、用户召回率这些核心指标日常关注。 哪些特征的用户的增加和流失,对平台的活跃、营收指标影响巨大。 场景1:广告投放 互联网内容领域,广告投放对保持日活、增加营收的影响非常巨大。 通过广告投放获取的这波新用户,是否具有消费潜力呢?要用什么样的内容做用户承接,通过什么关键路径能够实现留存和转化呢? 为了提高投放效果,算法部门会基于历史的用户数据训练用户留存、消费预测模型。 场景2:潜在流失用户挽留 具备什么样行为特征的是高潜流失用户呢?在什么时间节点对这些潜在流失用户进行召回、挽留,能够提高留存率,提高拉活率呢? 给出清晰的流失用户定义后,分析师和算法部门,可以构建一套直播用户流失预测模型。 基于模型,提取流失用户的特征,利用这些特征对用户进行挽留活动。 场景3:KA用户分析和运营 KA用户是直播行业里的重要运营和维护对象。 平台新来了一个用户,该用户能否成为成为平台营收的增长点呢?是否要在早期阶段进行服务的提升和关系维护呢? 在直播场景里,预测模型将能大大提升精细化运营的ROI。 三、感触比较深的点 1. 预览数据 高质量的数据是数据分析和挖掘的基础。 导入数据后,进行构建后,数据分析师能快速地了解数据的大体质量,不同特征的数据类型,有无缺失值,均值、众数等信息,大大减少了因为数据质量问题引发的后续的问题。
2. 构建后的简单特征关联度分析 通常情况下,特征的选取,是基于业务经验,系统也对这方面给出了快捷的特征影响分析,帮助分析师能筛除不必要的特征,加快模型构建速度。
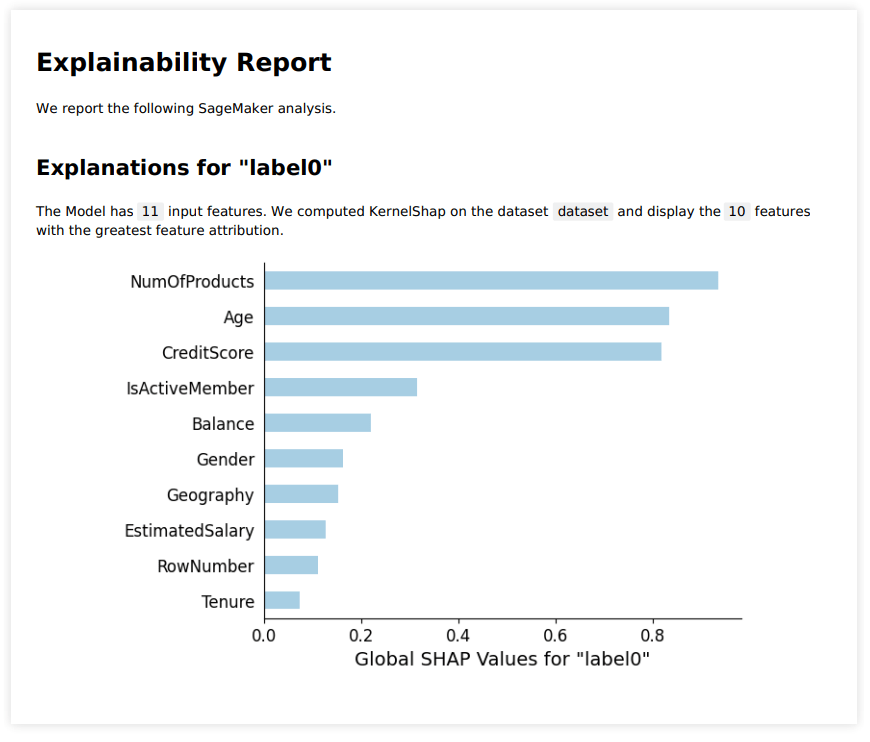
模型构建结束后,系统也基于 KernelShap 给出排名前十的影响模型预测结果的特征。
数据分析的同学,可以将更多的精力放在对关键特征、关键用户进行AB实验。 因为本人不具备算法模型构建的技能,所以Studio的部分,未进行深入体验。 四、其他体验 1. 视觉层面的感受 视觉层面有两个特点:简洁,不花哨;扁平化,不枯燥。 对比一些厂商的工具,可能因为产品调性问题,不会特别在意这些细节。 2. 交互层面 交互层面,也是比较便捷。在提醒方面,也是做得很好的。 操作指引给出了比较图形化的解释,和介绍中的很多点,都是有对应关系的。
比如:清理和分析数据并获得有关估算模型精度的指标,识别训练数据集中最具影响力的字段。 在导入了数据集之后,系统就给了我一些提示。
在预构建时,就给用户一些特征权重的提示。
3. 功能层面 模型管理的流程是:导入数据集 → 数据集自动检测 → 预构建(prebuild)→ 构建 → 预测 → 导出/共享。 在上文提到的交互提示下,操作起来没有任何难度。 模型构建完成后,也能方便地看到构建的细节,也能更数据科学家和算法工程师沟通,将模型构建的过程、脚本等等,都能进行共享,业务分析师职责范围内的工作难度被大大降低。
五、总结和感受 我觉得 Amazon SageMaker Canvas 这款产品拥有黑科技、定位清晰,紧盯目标,有边界感。 将复杂繁琐的特征工程、模型构建的过程进行产品化,为分析师解决了 80% 的常见问题,大大提高了效率。 剩余的、难搞的、但是也同样重要的模型调优,也可以跟数据科学家和算法工程师们进行协同。 数据分析师们将能大大地提升自工作效率,将更多的精力放到业务的驱动上。 作者:数据产品小lee;公众号:乐说乐言 本文来源【乐说乐言】版权归原作者所有 |

|

|

|

|

|


5月10日,虚拟偶像A-SOUL珈乐“直播休眠”话题阅读量破千万,并登上热搜。其实这并不...

今天,你居家办公了吗?疫情防控下,部分城市开启居家办公模式。家原本是生活休息的地...

今年 3 月份,我入职了字节跳动飞书团队,岗位是 aPaaS 产品,也就是低代码产品。在我...

身边有很多写SQL很厉害的数据分析人员,数据治理好了、对数据仓库、业务需求都很熟悉...

在电商爆火的今天,生活中所需要用到的上到“五金家居”下至“柴米油盐”的相关产品,...

这两天,许多设计人的朋友圈被老罗的一则视频刷屏。视频中,老罗“本色出演”一家企业...
转载部分的内容不涉及到商业行为,仅为提供转播信息之目的,版权归原作者所有,如有任何问题,联系更正删除。| QQ/WX:771661581 | 加微联系
三丰笔记 | 热传网 | 鄂ICP备2021016389号 | ©2021 www.izsf.cn
©2021 www.izsf.cn


